
Data Modeling in Databricks: The Complete Guide
From stakeholder interviews to production deployment - the 20% of knowledge that delivers 80% of results

Most data engineers struggle with data modeling because they treat it like a theoretical exercise. They spend weeks perfecting normalization, debating dimension granularity, and building elaborate data models that look beautiful on paper but fail in production because they don’t match how people actually query the data.
This guide will show you the practical, battle-tested approach to data modeling that covers 80% of real-world scenarios. You’ll learn how to gather requirements that matter, analyze what your users actually do (not what they say they do), choose the right modeling pattern, and validate before you build.
Topics covered:
Understanding the Problem
Step 1: Gathering Real Requirements
Step 2: Analyzing Current Usage Patterns
Step 3: Choosing the Right Modeling Approach for Databricks
Step 4: Designing for Common Access Patterns
Step 5: Validating Before Building
Common Mistakes and How to Avoid Them
Quick Reference for Daily Use
Key Takeaways
Next Steps
Understanding the Problem
Data modeling isn’t about creating the most normalized, academically correct schema. It’s about making data easy to query, understand, and maintain for your specific organization.
Here’s what that looks like in practice: imagine your business analysts want to answer “What were our top-selling products by region last quarter?” Without a proper data model, they need to join 8 tables, understand complex business logic scattered across different systems, and write 50-line SQL queries that take 10 minutes to run and cost $5 each. With a well-designed data model, that same question becomes a 5-line query that runs in 15 seconds and costs $0.10.
The difference? You built the model based on actual query patterns, not theoretical perfection.
This guide will walk you through the five critical steps that cover 80% of data modeling work:
Gathering real requirements (not just feature requests)
Analyzing current usage patterns (what users actually do)
Choosing the right modeling approach (star schema vs OBT vs Data Vault)
Designing for common access patterns (the 80% of queries)
Validating before building (catch problems early)
Step 1: Gathering Real Requirements
The Problem with Traditional Requirements Gathering
Most engineers ask stakeholders “What data do you need?” and get answers like “I need customer data” or “Give me all the sales information.” These aren’t requirements - they’re vague wishes. If you build based on these, you’ll create a data model that forces users to write complex queries for simple questions.
What to Ask Instead
Focus on questions they need to answer, not data they want to see. Here’s the framework:
Interview Template (30-minute session per stakeholder)
1. What business questions do you answer daily?
Not “What data do you use?” but “What decisions do you make?”
Example good answer: “I need to identify which products are underperforming in specific regions so I can adjust inventory”
Example bad answer: “I need the sales table”
2. Show me your top 5 most-run queries or reports
Get the actual SQL or BI tool queries
Identify the tables they join, filters they use, aggregations they need
Note which queries take too long or are too complex
3. How often do you need this data?
Real-time (< 5 min latency)
Near real-time (< 1 hour)
Daily batch
Weekly/monthly
This determines whether you need streaming, incremental, or batch updates.
4. At what grain do you analyze data?
Customer level? Product level? Daily? Hourly?
Example: “I need daily sales by product by store” = your fact table grain
This is THE most critical question - get this wrong and your model fails
5. What slows you down today?
“I have to join 12 tables to get customer lifetime value”
“I can’t get sales and returns in one query”
“The data is always 3 days old”
These pain points become your modeling priorities.
Documenting Requirements
Create a simple table like this:
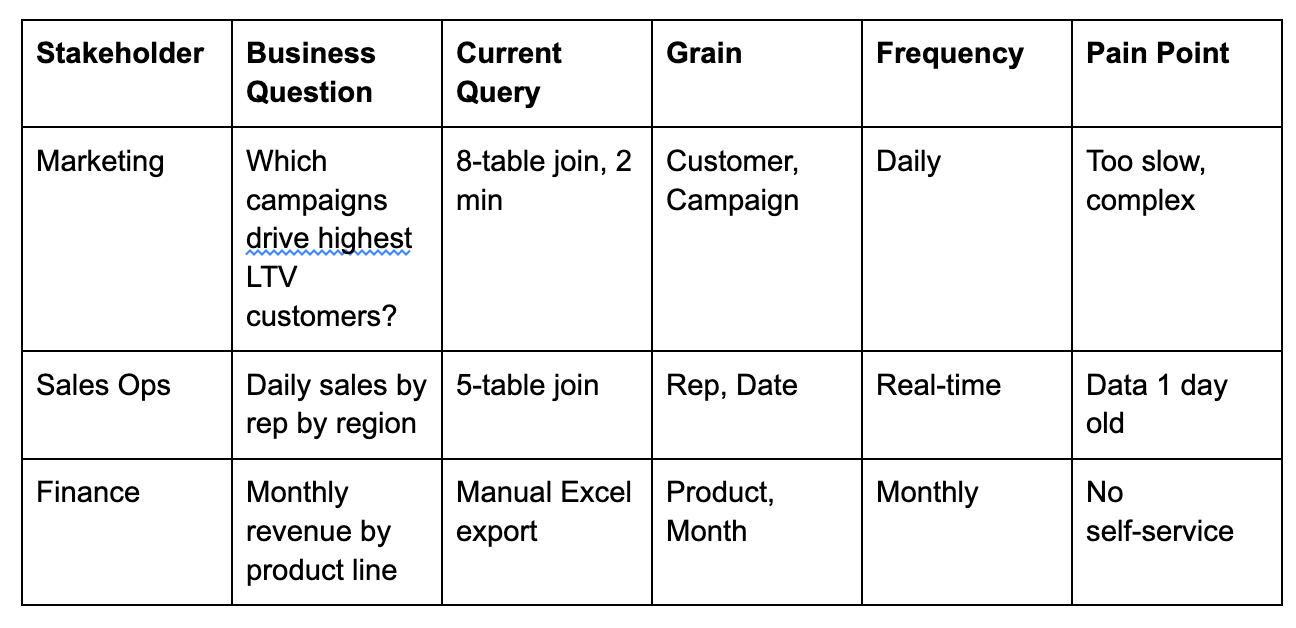
After 5-10 stakeholder interviews, you’ll see patterns emerge. Maybe 70% of questions involve customer+date+product dimensions. That tells you exactly what to optimize for.
Step 2: Analyzing Current Usage Patterns
Stakeholders often don’t know what they actually do. They’ll tell you they need real-time data, but when you check query logs, they run reports once a week. They’ll say they need 3 years of history, but 95% of queries filter to the last 30 days.
Don’t trust what people say - measure what they do.
