
The Databricks Technical Debt Navigation Guide: When to Ship and When to Perfect
The pragmatic judgment framework that senior engineers use to balance velocity and quality - with 8 real scenarios, decision templates, and a 30-day practice plan

Your 500GB Databricks pipeline needs tests. Business loses $50k/week waiting. Ship untested or delay 2 weeks? There's a third option most miss.
Most engineers see only those two choices.
Juniors either demand perfection (blocking shipping) or accept all debt (creating nightmares). Seniors balance: ship fast AND sustainable.
That pragmatic judgment is what leadership promotes. It's also completely learnable.
Here's the same situation, three approaches:
The Perfectionist (Blocks Shipping)
“We need 80% test coverage before this goes to production. No exceptions.”
Spending 3 weeks writing tests for edge cases that might never happen. Meanwhile, business loses $50K/week without the new pipeline processing customer data.
The Neglectful (Creates Nightmares)
“Tests slow us down. Ship it, we’ll add them later.” (Then never does)
Three months later: silent data quality issue affects 200 customer reports. Costs 40 hours to debug because no tests show what changed. CFO asks why this wasn’t caught.
The Pragmatic (Senior)
“We need tests for the critical path - schema validation, duplicate detection, and null handling. Edge cases can wait. Document what’s not tested and why.”
Their framework:
Assess risk: What breaks if this fails? (Customer reports = high visibility)
Calculate cost of delay: What’s waiting on this? ($50K/week revenue pipeline)
Identify critical path: What MUST work vs what’s edge case? (Happy path + error handling = 90% of scenarios)
Document intentional gaps: “Not tested: timezone edge cases (affects <1% of data), historical backfill scenarios (manual process)”
Example decision: “Pipeline processes 500GB daily customer transactions. Add 12 tests covering schema validation, duplicate detection, null handling, and basic aggregation logic. Document that retry logic and historical backfill aren’t tested yet - trigger for adding: if we see failures or backfills become common. Estimated: 3 hours to add those tests later.”
Result: Ships in 3 days instead of 3 weeks. Critical scenarios tested. Business gets value. Clear path for expanding coverage when needed.
The Pragmatic Judgment Playbook: 8 Real Scenarios
Let’s break down how this pragmatic approach works across the most common technical debt decisions Databricks engineers face. Each scenario shows the perfectionist trap, the neglectful trap, and the senior decision that ships fast while managing risk.
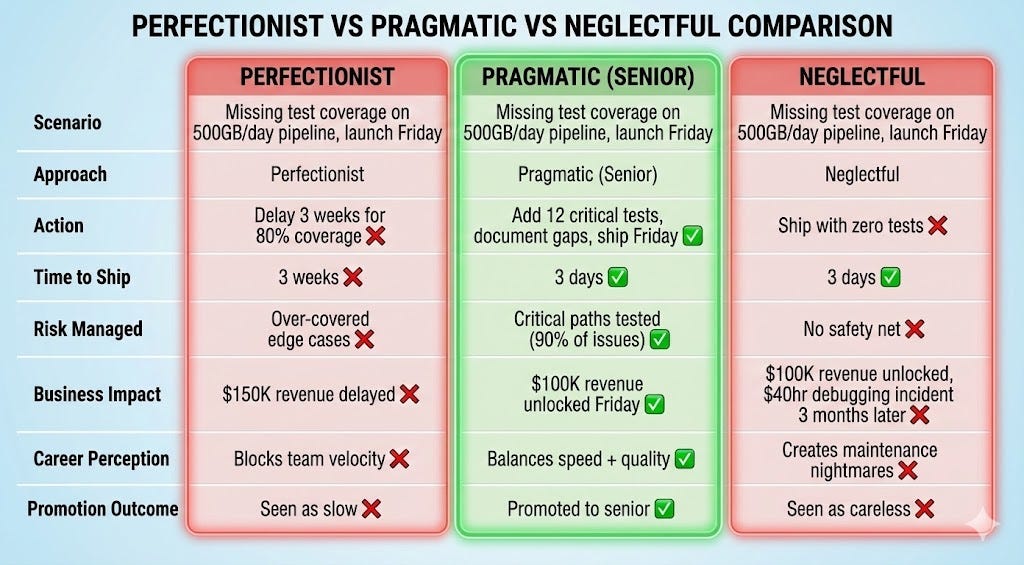
Scenario 1: Missing Test Coverage Pre-Launch
Situation: Pipeline processing 500GB daily customer transactions, zero tests, launch scheduled Friday for $100K/week revenue feature.
Perfectionist trap: “We need 80% coverage minimum. Delay launch 3 weeks to write comprehensive test suite covering all edge cases, integration tests, and performance benchmarks.”
Neglectful trap: “Tests slow us down. Ship it Friday, we’ll add tests next sprint.” (Next sprint comes, other priorities take over, tests never get written. Six months later, silent data corruption affects customer billing.)
Senior decision: “Add 12 focused tests covering critical path: schema validation (correct column types, required fields present), duplicate detection (primary key uniqueness), null handling (required fields not null), and basic aggregation logic (sum totals match expected ranges). Document what’s not tested: timezone edge cases (affects <1% of data), historical backfill scenarios (manual process, low frequency). Trigger for adding: if we see >3 production failures in these areas OR backfills become weekly. Estimated effort: 3 hours to add those tests later.”
Outcome: Ships Friday on schedule. $100K/week revenue unlocked. Critical scenarios tested (catch 90% of potential issues). Tech debt is documented with clear trigger for when to pay it down. Time saved: 3 weeks vs 3 days. Risk managed: critical paths covered, gaps documented.
Scenario 2: Legacy Code Discovered Mid-Feature
Situation: Adding feature to 5,000-line monolith Delta Live Tables pipeline. Code has no tests, unclear logic, processes $200K/day transactions. Feature due in 1 week.
Perfectionist trap: “This code is unmaintainable. Block feature work for 4 weeks while we refactor to modular architecture, add comprehensive tests, update to current patterns.”
Neglectful trap: “Add feature with minimal changes, ship it. Refactoring can wait.” (Six months later, monolith has grown to 8,000 lines, blocks 3 other features, no one dares touch it.)
Senior decision: “Extract the specific logic my feature needs into a separate, testable function. Add tests for that new function only. Document the boundary between clean code and legacy monolith with clear TODO: ‘Refactor trigger: if 2+ additional features need to touch this core logic, extract to separate pipeline. Estimated: 5 days.’ Ship feature on time.”
Outcome: Feature ships in 1 week. New code is tested and maintainable. Legacy monolith unchanged (risk contained). Clear refactor trigger prevents unbounded growth. Time saved: 4 weeks of refactoring avoided. Risk managed: new code isolated, trigger prevents runaway debt.
Scenario 3: Non-Optimal Performance
Situation: Databricks SQL query takes 30 seconds, could be optimized to 5 seconds with Z-Ordering and better partitioning. Query runs once per day for internal analytics dashboard (10 users).
Perfectionist trap: “Unacceptable performance. Spend 2 days analyzing query plans, implementing Z-Ordering, tuning partition strategy, benchmarking improvements before shipping dashboard.”
Neglectful trap: “It works, ship it. Performance is good enough.” (Three months later, dashboard expanded to 50 queries, all slow. Users complain, leadership questions platform choice.)
Senior decision: “Query runs once daily for internal tool with 10 users. 30 seconds is acceptable for now. Document performance baseline and optimization path: ‘TODO: If usage grows to >50 users OR queries run >10x/day OR query time >1 minute, implement Z-Ordering on date column and repartition by region. Estimated: 4 hours.’ Monitor query frequency in system tables.”
Outcome: Dashboard ships immediately. Users get value today. Optimization deferred until usage justifies investment. Clear trigger prevents drift. Time saved: 2 days of premature optimization. Risk managed: performance threshold documented, monitoring in place.
